Baoguang Shi, Xiang Bai, Cong Yao의 'An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition' 논문을 읽고 정리해 보고자 한다.
[Abstract]
이미지 기반 sequence recognition. 해당 논문에서는 scene text recognition(STR)의 문제에 대해 살펴보고, 본 논문의 방법론을 제안함. 특징 추출, 시퀀스 모델링, 그리고 transcription을 통합된 프레임워크로 통합시키는 neural network 구조를 제안한다. 기존의 STR과 비교했을 때, 제안된 구조는 4가지 구분되는 특징을 보유하고 있다.
(1) end-to-end trainable. (vs separately trained and tuned)
(2) 문자 분할이나(character segmentation) 수평 스케일 정규화(horizontal scale normalization)를 포함하지 않는 임의의 길이의 시퀀스를 자연스럽게 처리한다.
(3) 사전 정의된 어휘에만 국한되지 않고, 사전이 없는 장면 및 사전 기반 장면 text recognition 작업 모두에서 놀라운 성능을 달성할 수 있다.
(4) 효과적이지만 훨씬 더 작은 모델을 생성하며, 따라서 실제 현실 적용 시나리오에서 보다 실용적일 수 있다.
Standard benchmark 실험은 IIIT-5K, Street View Text and ICDAR dataset을 사용해 수행했다.
** STR - 일상 속 텍스트를 인식하고 싶을 때 주로 사용. 글자 영역을 찾는 Text Recognition과 영역 속 글자를 인식하는 Recognition 과정을 거치며, End-to-End Scene Text Detection & Recognition(=Text Spottig)은 Detection과 Recogition 전 과정을 의미한다.
[1. Introduction]
해당 논문은 computer vision의 클래식한 문제 : image based sequence recognition를 다루었다. 일반적인 object recognition과 다르게, sequence-like object를 인식하는 것은 종종 하나의 label이 아닌 다수의 object label을 예측하는 형태로 받아들일 수 있다. 또 다른 sequence-like object의 특징은 그들의 길이가 굉장히 다를 수 있다는 점이다. 예를 들면, 2글자만으로 이루어진 "OK", 15글자로 이루어진 "congratulations" 단어들이 모두 영단어에 포함되어 있다. 따라서 가장 대표적인 DCNN과 같은 모델은 sequence prediction에 직접적으로 적용되기 어렵다. DCNN 모델들은 종종 고정된 자수의 입력, 출력에서 작동하므로 가변 길이의 레이블 시퀀스를 생성할 수 없기 때문이다.
RNN(Recurrent Neural Networks) 모델들은 sequences를 주로 다룰 수 있는 모델이며, RNN모델의 장점 중 하나는 훈련과 테스트 모두에서 sequence object image에서 각 요소의 위치가 필요하지 않다는 것이다. 하지만 input object image를 sequence of image features로 변형하는 독립적인 전처리 과정이 대부분 필수적이다. 따라서 현존하는 RNN에 기반한 시스템들은 end-to-end의 의미로 학습되고 최적화되기에는 충분치 않다.
해당 논문에서는 이미지로부터 sequence-like object를 인지하는데에 특화된 novel neural network model에 해당하는 network 구조에 주목했다. 본 논문에서는 DCNN과 RNN을 결합해 만들어진 CRNN(Convolutional Recurrent Neural Network)를 주로 사용했다. Sequence-like object에 대해 CRNN은 CNN 모델들보다 몇가지 특징적인 장점을 보유하고 있다.
(1) 추가적인 detailed annotation(ex, characters) 따로 없이도 직접적으로 sequence labels(ex, words)만으로 학습될 수 있다.
(2) 이미지 데이터로부터 직접적으로 informative representation를 학습하는 데 DCNN과 동일한 특서을 가지며, binarization/segmentation, component localization 등을 포함한 전처리 과정이나 hand-craft features들이 필요하지 않다.
(3) sequence of labels를 생성할 수 있어 RNN과 동일한 특징을 보유한다.
(4) 학습과 테스트 단계에서 height normalization만 있다면 sequence-like objects의 길이에 구애받지 않고 학습이 가능하다.
(5) scene text에 대해서는 더 좋은, 그리고 비견될 만한 성능을 달성했다.
(6) 일반적인 DCNN 모델들보다 훨씬 적은 모수를 가지고 있기 때문에 훨씬 저장공간을 적게 소모한다.
[2. The Proposed Network Architecture]
CRNN의 Network architecture는 아래와 같다.
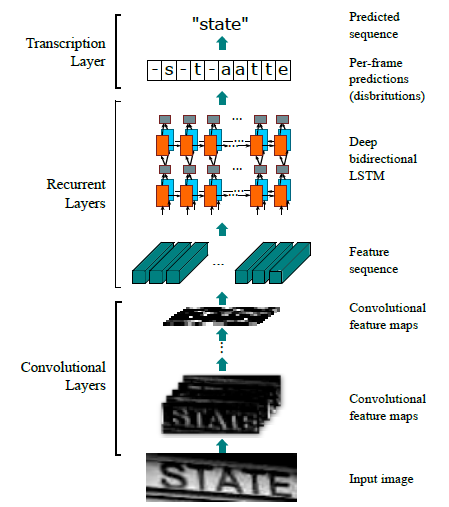
총 3가지 파트로 나뉘어져 있음.
(1) convolutional layer - input image로부터 feature sequence를 추출함
(2) Reccurent layers - 각 frame에서 label distribution을 예측함.
(3) Trascription layer - 각 frame label 예측결과들을 final label sequence로 번역함.(translates)
가장 아랫단인 Convolution layer에선 각 input image들로부터 feature sequence를 추출해낸다.
그 위에는 Recurrent Network를 구성해서 각 feature sequence의 각 frame들의 prediction을 수행한다.
가장 마지막 단인 transcripton layer는 per-frame 예측결과들을 label sequence로 번역한다.
[2.1 Feature Sequence Extraction]
CRNN모델에서 convolutional layers의 요소는 일반적인 CNN의 convolutional과 max-pooling layers로 구성되어있다. 해당 요소들은 input image로부터 sequential feature representation을 추출하기 위해 사용된다. network에 들어가기 전에, 모든 inpt 이미지는 동일 높이로 스케일 조정이 필요하다. 이후 convolutional layer의 component에 의해 생성된 feature map들로부터 sequence of feature vectors를 추출 할 수 있다. 이후 이는 RNN의 input으로 사용된다. 특히 feature sequence의 각 feature vector는 feature map에서 열별로 왼쪽에서 오른쪽으로 생성된다. 이는 즉, $i$-th feature vector는 곧 모든 map들의 $i$-th 열들의 연결임을 의미한다. 현재 세팅에서 각 열들의 너비는 single pixel로 고정되어있다.
convolution, max-pooling, 그리고 요소별 활성화 함수의 layer들이 local region에서 작동하므로, 변환 불변이다. 따라서 각 feature map들의 열은 기존 이미지의 직사각형 영역에 해당하며(receptive field), 해당 직사각형 영역은 feature map들에서의 왼쪽에서 오른쪽 방향의 각 열들의 순서에 상응한다. 아래 그림을 보면 쉽게 이해된다.


'NLP' 카테고리의 다른 글
| [Day3] 한권으로 끝내는 실전 LLM 파인튜닝 - 멀티헤드 어텐션과 피드포워드 (4) | 2025.01.03 |
|---|---|
| [CS224N] Lecture 5: Recurrent Neural Networks RNNs (2) | 2024.04.21 |
| [CS224N] Lecture 2: Word Vectors, Word Senses, and Neural Network Classifiers (0) | 2024.03.26 |
| Subword Tokenizer - BPE, WordPiece (0) | 2022.05.29 |
| StarSpace (3) | 2022.04.17 |



